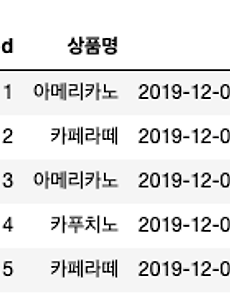
[pandas] 특정 key를 기준으로 groupby 한 후 해당목록 배열(dict)로 변경하기
Grid 형식의 데이터에 Key를 지정하여 관련 값을 배열로 넣고 싶을떄 쓰면 된다. 여기서는 예로 주소를 썼다. 가령 서울시에 포함되는 구들을 배열로 만들고 싶은 경우다 아래 원본데이터와 변경하고 싶은 데이터를 보면 이해될 거 같다. 이번 포스팅을 수행하기 위해 샘플 파일을 여기 첨부해두겠다. CSV 내 데이터 형태 바꾸고 싶은 문자형 { '광주광역시':['광산구', '남구', '동구', '북구', '서구'] ,'대구광역시':['남구', '달서구', '달성군', '동구', '북구', '서구', '수성구', '중구'] ,'대전광역시':['대덕구', '동구', '서구', '유성구', '중구'] ... } 그럼 pandas 를 켜서 다음을 수행한다. sample = pd.read_csv('address-sa..
2020. 5. 30.
[pandas] 특정 key를 기준으로 groupby 한 후 해당목록 배열(dict)로 변경하기
Grid 형식의 데이터에 Key를 지정하여 관련 값을 배열로 넣고 싶을떄 쓰면 된다. 여기서는 예로 주소를 썼다. 가령 서울시에 포함되는 구들을 배열로 만들고 싶은 경우다 아래 원본데이터와 변경하고 싶은 데이터를 보면 이해될 거 같다. 이번 포스팅을 수행하기 위해 샘플 파일을 여기 첨부해두겠다. CSV 내 데이터 형태 바꾸고 싶은 문자형 { '광주광역시':['광산구', '남구', '동구', '북구', '서구'] ,'대구광역시':['남구', '달서구', '달성군', '동구', '북구', '서구', '수성구', '중구'] ,'대전광역시':['대덕구', '동구', '서구', '유성구', '중구'] ... } 그럼 pandas 를 켜서 다음을 수행한다. sample = pd.read_csv('address-sa..
2020. 5. 30.